Detection, segmentation, and 3D pose estimation of surgical tools using convolutional neural networks and algebraic geometry
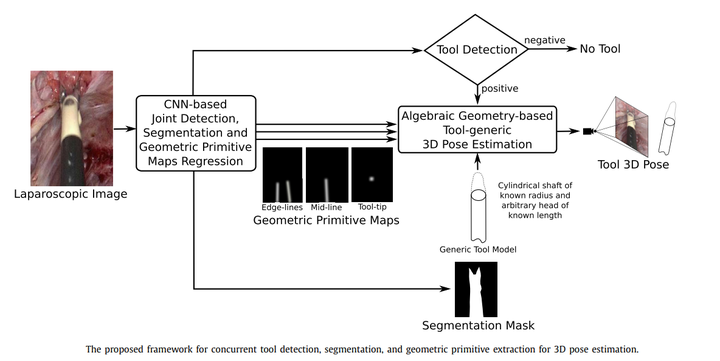 Proposed framework for concurrent tool detection, segmentation, and geometric primitive extraction
Proposed framework for concurrent tool detection, segmentation, and geometric primitive extraction
Abstract
Surgical tool detection, segmentation, and 3D pose estimation are crucial components in Computer-Assisted Laparoscopy (CAL). The existing frameworks have two main limitations. First, they do not integrate all three components. Integration is critical; for instance, one should not attempt computing pose if detection is negative. Second, they have particular requirements, such as the availability of a CAD model. We propose an integrated and generic framework whose sole requirement for the 3D pose is that the tool shaft is cylindrical. Our framework makes the most of deep learning and geometric 3D vision by combining a proposed Convolutional Neural Network (CNN) with algebraic geometry. We show two applications of our framework in CAL: tool-aware rendering in Augmented Reality (AR) and tool-based 3D measurement. We name our CNN as ART-Net (Augmented Reality Tool Network). It has a Single Input Multiple Output (SIMO) architecture with one encoder and multiple decoders to achieve detection, segmentation, and geometric primitive extraction. These primitives are the tool edge-lines, mid-line, and tip. They allow the tool’s 3D pose to be estimated by a fast algebraic procedure. The framework only proceeds if a tool is detected. The accuracy of segmentation and geometric primitive extraction is boosted by a new Full-resolution feature map Generator (FrG). We extensively evaluate the proposed framework with the EndoVis and new proposed datasets. We compare the segmentation results against several Fully Convolutional Networks (FCN) and U-Net variants. Several ablation studies are provided for detection, segmentation, and geometric primitive extraction. The proposed datasets are surgery videos of different patients. In detection, ART-Net achieves 100.0% in both average precision and accuracy. In segmentation it achieves 81.0% in mean Intersection over Union (mIoU) on the robotic EndoVis dataset (articulated tool), where it outperforms both FCN and UNet by 4.5pp and 2.9pp, respectively. It achieves 88.2% mIoU on the remaining datasets (non-articulated tool). In geometric primitive extraction, ART-Net achieves 2.45 degrees and 2.23 degrees in mean Arc Length (mAL) error for the edge lines and mid-line, respectively, and 9.3 pixels in mean Euclidean distance error for the tooltip. Finally, regarding the 3D pose evaluated on animal data, our framework achieves 1.87 mm, 0.70 mm, and 4.80 mm mean absolute errors on the X, Y, and Z coordinates, respectively, and 5.94∘ angular errors on the shaft orientation. It achieves 2.59 mm and 1.99 mm in the tool head’s mean and median location error evaluated on patient data. The proposed framework outperforms existing ones in detection and segmentation. Compared to separate networks, integrating the tasks in a single network preserves accuracy in detection and segmentation but substantially improves accuracy in geometric primitive extraction. Our framework has similar or better accuracy in 3D pose estimation while improving robustness against laparoscopy’s very challenging imaging conditions.