Missing value imputation affects the performance of machine learning: A review and analysis of the literature (2010–2021)
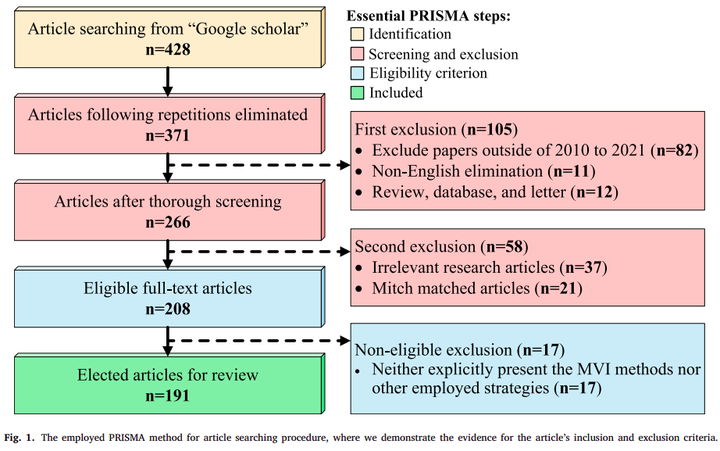 Proposed framework
Proposed framework
Abstract
Recently, numerous studies have been conducted on Missing Value Imputation (MVI), intending the primary solution scheme for the datasets containing one or more missing attribute’s values. The incorporation of MVI reinforces the Machine Learning (ML) models’ performance and necessitates a systematic review of MVI methodologies employed for different tasks and datasets. It will aid beginners as guidance towards composing an effective ML-based decision-making system in various fields of applications. This article aims to conduct a rigorous review and analysis of the state-of-the-art MVI methods in the literature published in the last decade. Altogether, 191 articles, published from 2010 to August 2021, are selected for review using the well-known Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) technique. We summarize those articles with relevant definitions, theories, and analyses to provide essential information for building a precise decision-making framework. In addition, the evaluation metrics employed for MVI methods and ML-based classification models are also discussed and explored. Remarkably, the trends for the MVI method and its evaluation are also scrutinized from the last twelve years’ data. To come up with the conclusion, several ML-based pipelines, where the MVI schemes are incorporated for performance enhancement, are investigated and reviewed for many different datasets. In the end, informative observations and recommendations are addressed for future research directions and trends in related fields of interest.