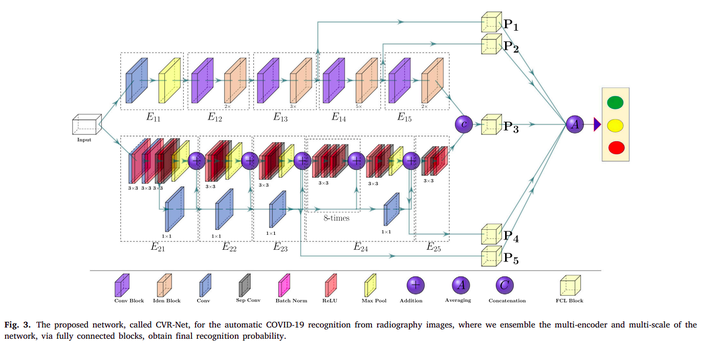
 Proposed framework
Proposed framework
Abstract
Since the COVID-19 pandemic, several research studies have proposed Deep Learning (DL)-based automated COVID-19 detection, reporting high cross-validation accuracy when classifying COVID-19 patients from normal or other common Pneumonia. Although the reported outcomes are very high in most cases, these results were obtained without an independent test set from a separate data source(s). DL models are likely to overfit training data distribution when independent test sets are not utilized or are prone to learn dataset-specific artifacts rather than the actual disease characteristics and underlying pathology. This study aims to assess the promise of such DL methods and datasets by investigating the key challenges and issues by examining the compositions of the available public image datasets and designing different experimental setups. A convolutional neural network-based network, called CVR-Net (COVID-19 Recognition Network), has been proposed for conducting comprehensive experiments to validate our hypothesis. The presented end-to-end CVR-Net is a multi-scale-multi-encoder ensemble model that aggregates the outputs from two different encoders and their different scales to convey the final prediction probability. Three different classification tasks, such as 2-, 3-, 4-classes, are designed where the train–test datasets are from the single, multiple, and independent sources. The obtained binary classification accuracy is 99.8% for a single train–test data source, where the accuracies fall to 98.4% and 88.7% when multiple and independent train–test data sources are utilized. Similar outcomes are noticed in multi-class categorization tasks for single, multiple, and independent data sources, highlighting the challenges in developing DL models with the existing public datasets without an independent test set from a separate dataset. Such a result concludes a requirement for a better-designed dataset for developing DL tools applicable in actual clinical settings. The dataset should have an independent test set; for a single machine or hospital source, have a more balanced set of images for all the prediction classes; and have a balanced dataset from several hospitals and demography. Our source codes and model are publicly available1 for the research community for further improvements.