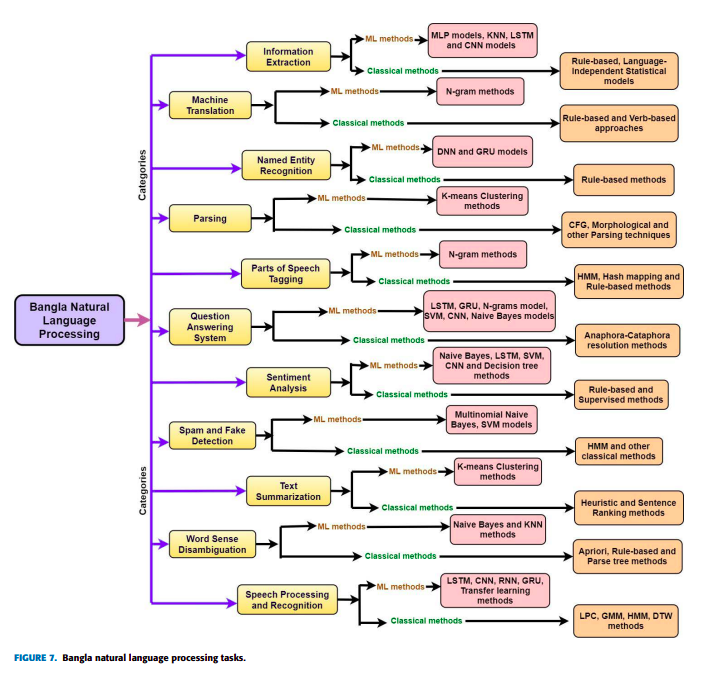
Bangla Natural Language Processing: A Comprehensive Analysis of Classical, Machine Learning, and Deep Learning Based Methods
 Proposed framework
Proposed framework
Abstract
The Bangla language is the seventh most spoken language, with 265 million native and non-native speakers worldwide. However, English is the predominant language for online resources and technical knowledge, journals, and documentation. Consequently, many Bangla-speaking people, who have limited command of English, face hurdles to utilize English resources. To bridge the gap between limited support and increasing demand, researchers conducted many experiments and developed valuable tools and techniques to create and process Bangla language materials. Many efforts are also ongoing to make it easy to use the Bangla language in the online and technical domains. There are some review papers to understand the past, previous, and future Bangla Natural Language Processing (BNLP) trends. The studies are mainly concentrated on the specific domains of BNLP, such as sentiment analysis, speech recognition, optical character recognition, and text summarization. There is an apparent scarcity of resources that contain a comprehensive review of the recent BNLP tools and methods. Therefore, in this paper, we present a thorough analysis of 75 BNLP research papers and categorize them into 11 categories, namely Information Extraction, Machine Translation, Named Entity Recognition, Parsing, Parts of Speech Tagging, Question Answering System, Sentiment Analysis, Spam and Fake Detection, Text Summarization, Word Sense Disambiguation, and Speech Processing and Recognition. We study articles published between 1999 to 2021, and 50% of the papers were published after 2015. Furthermore, we discuss Classical, Machine Learning and Deep Learning approaches with different datasets while addressing the limitations and current and future trends of the BNLP.