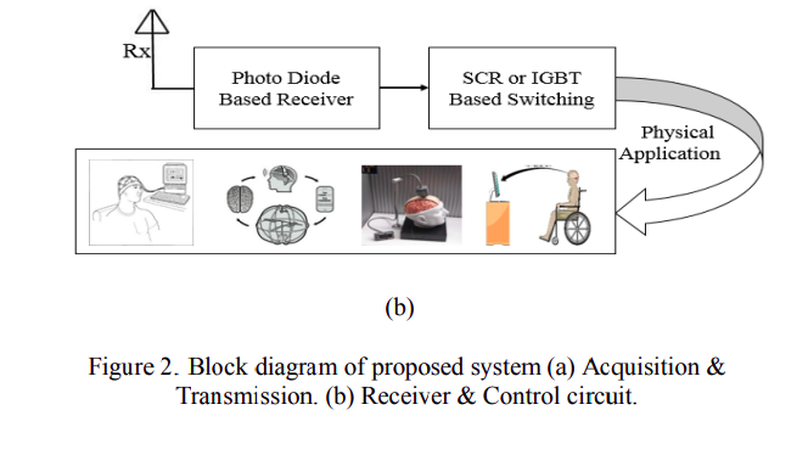
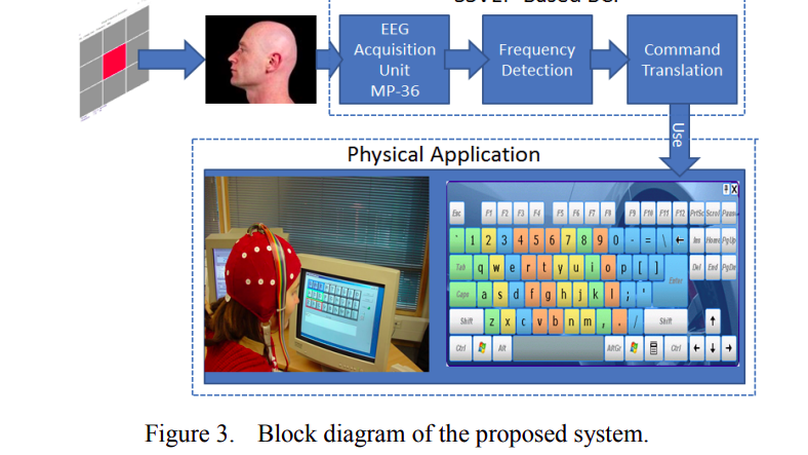
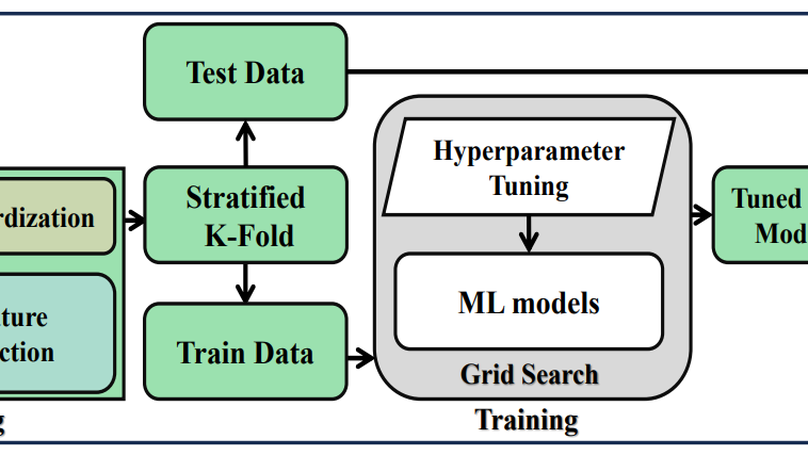
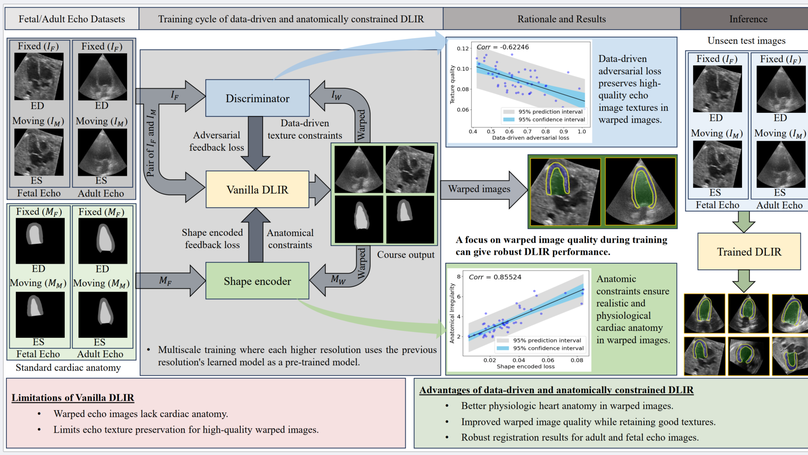
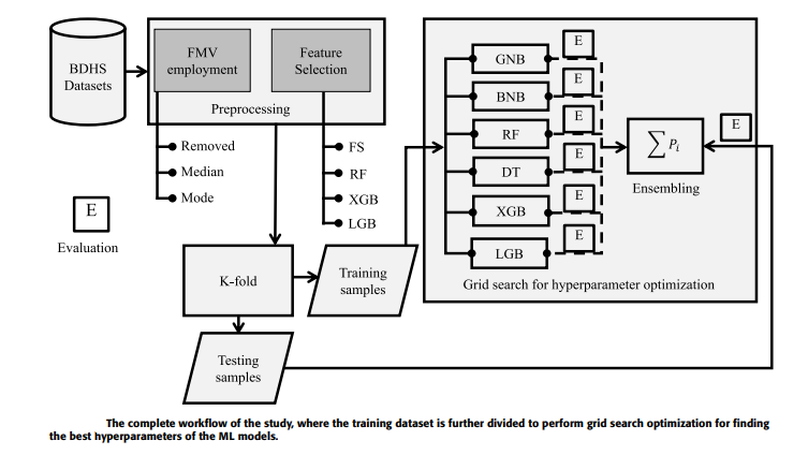
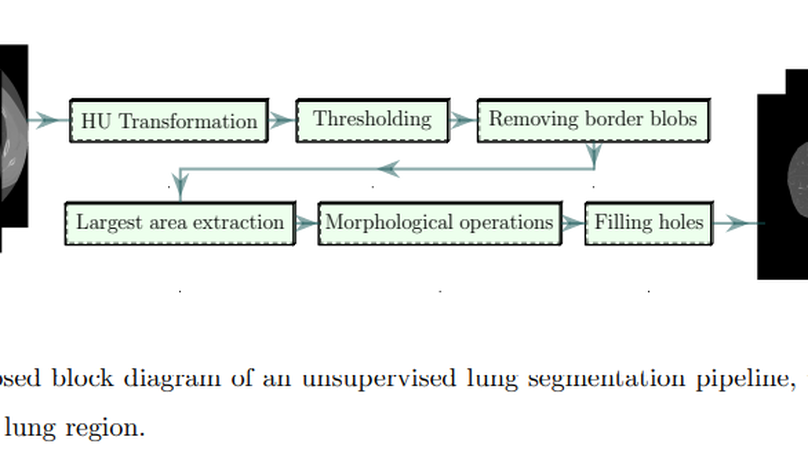
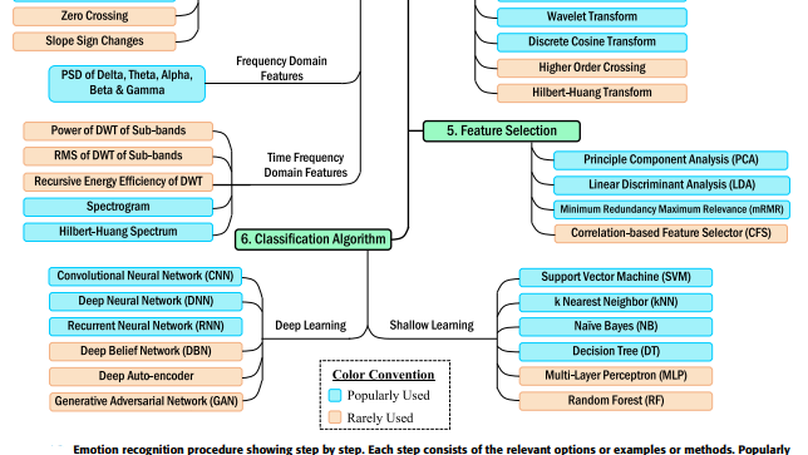
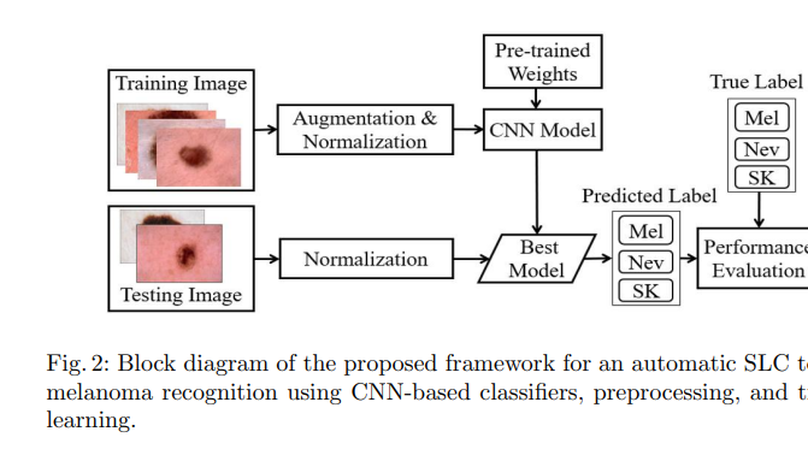
Publications
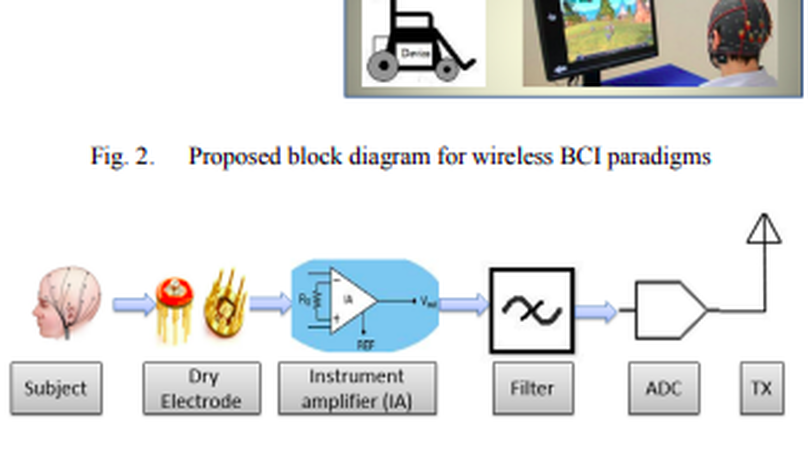
BCIs, which elaborated as Brain-computer Interface that use brain responses to control the BCI paradigms. These brain responses are measured using Electroencephalographic signal along the scalp of the subjects. However, the less variability of EEG signal from the subjects make the BCI paradigms user independent. In this research, we simply analyze the user independency of SSVEP based EEG signal that makes a conclusion inter subject’s variability of BCI users. To accomplish the research goal, SSVEP based EEG signal extract from both different subjects and different stimulation conditions and a features vector is formed to compare each subject’s variability. Artificial Neural Network classifier is used to determine the deviation and regression of deviation of each features vectors. From the heatmap and classifier, it is found that the used independency of the EEG signal is less that means that less variability of EEG. That ensures the user independent BCI paradigms with high transfer rate of the bits.
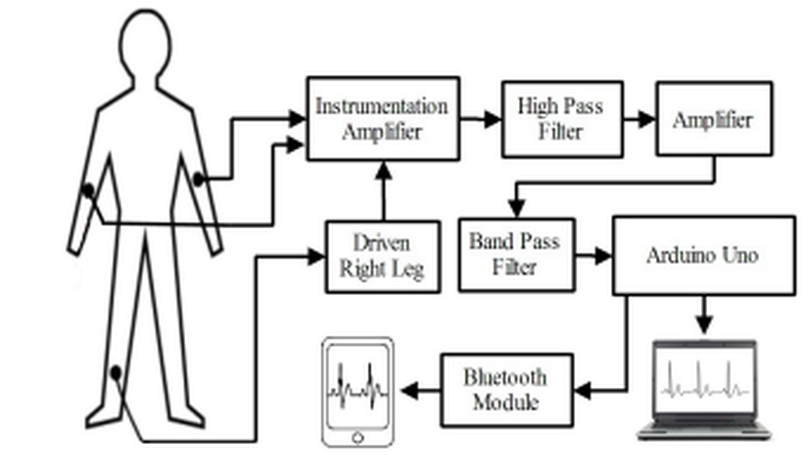
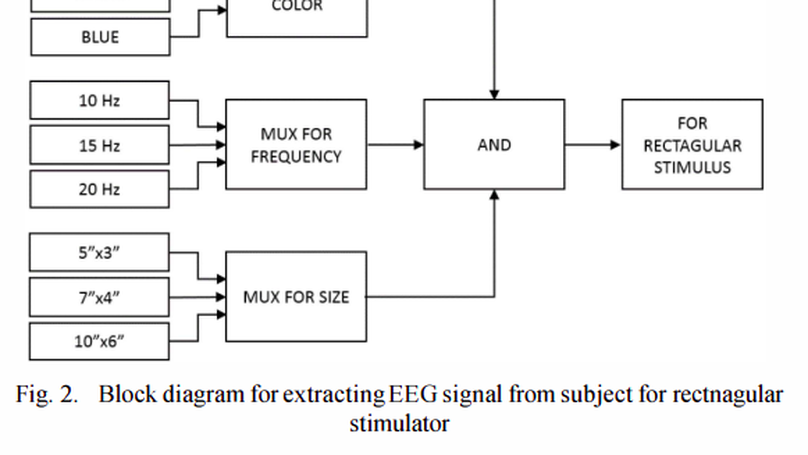
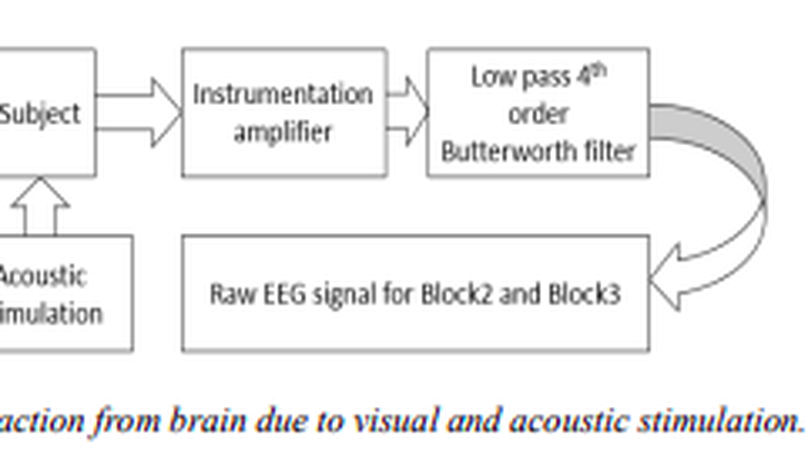
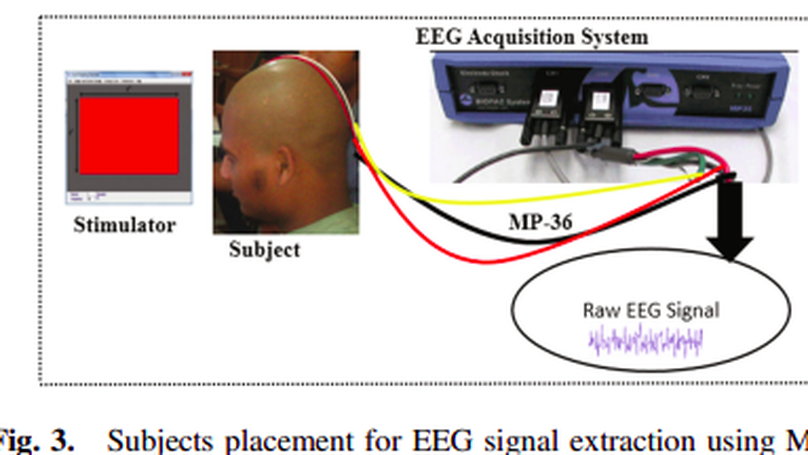
Brain-computer Interfaces (BCIs) are the communicating bridges between the human brain and a computer which may be implemented on the basis of Steady-state Visual Evoked Potentials (SSVEPs). It is mandatory to improve the stimulation for the betterment of the accuracy of modern BCIs, higher Information Transfer Rate (ITR), desired bandwidth (BW), and Signal to Noise Ratio (SNR) of BCIs. The performance of stimulator depends on many factors such as size and shape of stimulator, frequency of stimulation, luminance, color, and subject attention. Information Transfer Rate (ITR) varies with the change of frequency and size of the visual stimuli. In our research, a Circular Repetitive Visual Stimulator (CRVS) of different diameters (2″, 2.5″ and 3″), colors (RGB), frequencies (10, 15 and 20 Hz) was used. The raw EEG signal is processed for finding the effect of diverse stimulation on alpha band of EEG signal at diverse condition. From the analysis it is found that, when the size of the stimulator changes from 2″ to 2.5″, resultant increase in alpha wave is 58.18%. But for a further increase in size from 2.5″ to 3″, there is a resultant decrease in alpha wave of 45%. Similar result is found for the changes in frequencies and colors.